
Posted on October 21, 2025 | By: Scrollunlock.in | Category: Cloud Computing
In the pre-dawn hours of October 20, 2025, the internet blinked. Snapchat feeds froze, Fortnite lobbies emptied, Venmo payments stalled, and even Alexa went silent for thousands. The culprit? A seemingly innocuous DNS glitch in Amazon Web Services’ (AWS) crown jewel: the US-EAST-1 region. But this wasn’t just another blip—it was a stark reminder of how a single thread can unravel an entire digital tapestry. Let’s dive into what happened, why it snowballed, and what it means for the cloud-dependent world.
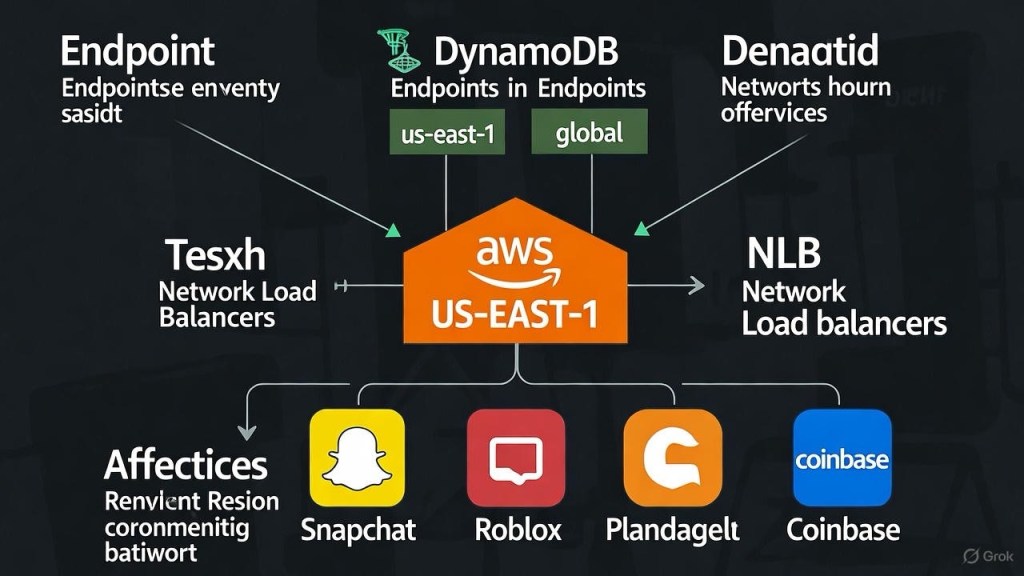
The Epicenter: US-EAST-1 and DynamoDB’s Hidden Power
Nestled in Northern Virginia, US-EAST-1 isn’t just a data center—it’s the data center. Hosting over a third of AWS’s global compute capacity, it underpins everything from Netflix binges to federal government ops. When things go wrong here, the world notices.
Enter DynamoDB, AWS’s serverless NoSQL database darling. Beloved for its scalability, it’s not just for customer apps; it’s the unsung hero of AWS’s internals. Metadata, user states, service configs—you name it, DynamoDB stores it. On October 19 at 11:49 PM PDT, error rates spiked for DynamoDB API calls. Why? DNS resolution failed. Clients (both external apps and internal AWS services) couldn’t “find” the endpoints. It was like mailing a letter without an address: chaos ensued.
Within minutes, the ripple hit. Over 36 AWS services—EC2 for virtual machines, SQS for queues, IAM for access control—ground to a halt. Global tables in DynamoDB, which sync data across regions, faltered too. By 12:11 AM PDT, AWS’s Health Dashboard lit up like a Christmas tree, warning of “increased error rates and latencies” across the board. 0 Downstream? Coinbase couldn’t process trades, Ring doorbells went dark, and Slack teams stared at loading screens. 1
The Vicious Cycle: Retries, Timeouts, and Echoes of 2015
This wasn’t random. DNS failures create a textbook feedback loop, and this one played out predictably. Unable to resolve endpoints, clients retried requests—hammering servers with redundant traffic. Timeouts bred more retries, spiking resource consumption and worsening latencies. Sound familiar? It’s a near-replay of the September 2015 DynamoDB outage, where similar retry storms cascaded into hours of downtime. 3
By 12:26 AM PDT, AWS pinpointed the trigger: DNS woes for DynamoDB’s regional endpoints. 1 What started as a localized DNS hiccup in US-EAST-1 metastasized because of interdependence. AWS services aren’t silos; they’re a web of shared data. When DynamoDB coughs, the whole ecosystem wheezes.
AWS’s War Room: Parallel Paths to Recovery
Credit where due: AWS didn’t freeze. Instead of hunting one “root cause,” they unleashed parallel fixes—a hallmark of modern incident response. 3 At 2:01 AM PDT, they announced progress on DNS stabilization. Engineering teams likely:
- Restarted/Reconfigured DNS Resolvers: Flushing caches and rebooting handlers to restore endpoint visibility.
- Rerouted Queries: Shifting traffic to backup resolution paths, bypassing the faulty chain.
- Emergency Caching Tweaks: Forcing temporary DNS records to prevent further resolution fails.
The primary DNS issue cleared by 2:24 AM PDT, but a knockout punch lingered: EC2 instance launches stalled, thanks to their DynamoDB dependency for metadata. 5 Full recovery trickled in by 5:27 AM ET, with most services humming again by midday. 4 Total downtime? Under three hours for the core blast, but backlogs meant some pains persisted into the evening.
Lessons from the Fragile Cloud: Interdependence Isn’t Optional—It’s a Risk
This outage, the third big US-EAST-1 meltdown in five years, 6 exposes the double-edged sword of cloud scale. Pros: Infinite scalability, global reach. Cons: Single points of failure that can cascade in minutes. Financial hit? Likely $100M+ in lost productivity and revenue, from stalled e-commerce to frozen fintech. 4
For devs and architects, takeaways are clear:
- Multi-Region Everything: Don’t bet the farm on US-EAST-1. Use global tables wisely and failover to EU-WEST-1 or AP-SOUTHEAST-2.
- Circuit Breakers and Backoffs: Implement exponential retry logic to starve feedback loops.
- Chaos Engineering: Proactively simulate DNS fails with tools like Gremlin to harden your stack.
- Diversify Providers: AWS is king (30% market share), 5 but blending in GCP or Azure spreads risk.
Additionally: AWS Service Health Dashboard
For real-time updates on the AWS outage (including the recent US-EAST-1 issues affecting DynamoDB and related services), visit the official AWS Health Dashboard:
• Global Service Health Overview: https://health.aws.amazon.com/
This provides a public view of ongoing events, planned maintenance, and service disruptions across all AWS regions. As of October 21, 2025, it shows the core issues as mitigated, with some services still recovering from backlogs.
If you have an AWS account, log in for a personalized Personal Health Dashboard view, which includes account-specific alerts and guidance. For broader outage tracking, you can also check Downdetector’s AWS page for user-reported issues.
These dashboards are the most reliable sources for status updates. If you’re experiencing issues with a specific service, search within the dashboard for details.
AWS will post a postmortem soon, no doubt with mitigations like enhanced DNS redundancy. Until then, this is a wake-up: The cloud is robust, but not invincible. In a world where downtime costs $5K+ per minute for big players, fragility isn’t abstract—it’s expensive.
What do you think—over-reliance on one provider, or just growing pains? Drop a comment below. Stay resilient out there.
Sources: AWS Health Dashboard, Reuters, CNBC, and more. All times PDT unless noted.

Leave a comment